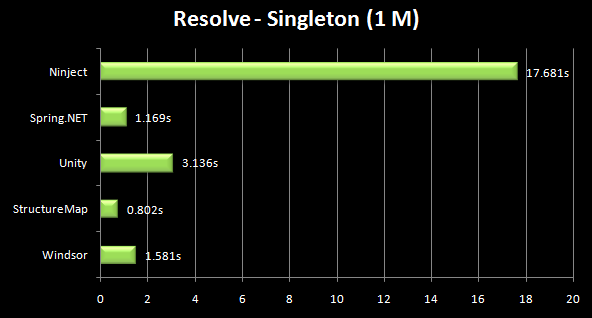
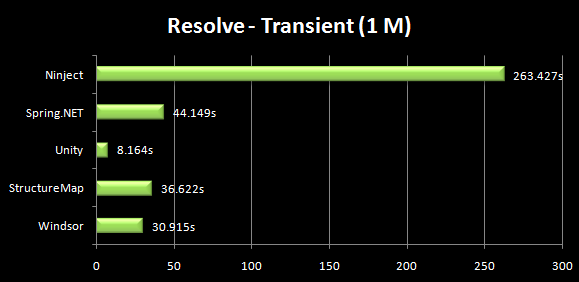
I am currently trying to prototype how a portal application could be build using ASP.NET MVC (I would prefer to use MonoRail but can't).
There is a big problem in the way the default implementation of the IControllerFactory is handling controller types. It is using a simple dictionary to map controller names to controller types. The key in the dictionary is only the controller name (like "Home" for a HomeController type), this means that you cannot have controllers with the same type name (no matter what namespace or assembly the controller is in). In big applications you probably want to group your controllers into areas in which case a controller of the same name could be likely.
So currently it is not possible to group controllers into what MonoRail calls Areas. To do this you would have to implement IControllerFactory from scratch since the root of the problem is the ControllerTypeCache which is being used by the DefaultControllerFactory, and the ControllerTypeCache is of course internal and sealed. There are probably other changes that would need to be made to introduce the concept of areas.
There is a extensibility point named IViewLocator used by the WebFormViewEngine which can be exchanged to change the way the view engine locates views. A simple example:
public class PortalViewLocator : ViewLocator { public PortalViewLocator () { ViewLocationFormats = new[] { "~/CustomViewDir/{1}/{0}.aspx", "~/CustomViewDir/{1}/{0}.ascx", "~/CustomViewDir/Shared/{0}.aspx", "~/CustomViewDir/Shared/{0}.ascx" }; MasterLocationFormats = new[] { "~/CustomViewDir/{1}/{0}.master", "~/CustomViewDir/Shared/{0}.master" }; } }
To solve the problem with controller areas MonoRail has something it calls a Controller Tree which serves the same role as the ASP.NET MVC ControllerTypeCache. In MonoRail the area of a controller is specified using the optional ControllerDetails attribute:
using Castle.MonoRail.Framework; [ControllerDetails(Area="admin")] public class UsersController : Controller { public void Index() { } }With the default routing the above index function would correspond the URL "/admin/users/index". If ASP.NET MVC adopted a similar approach it could check for an attribute in it's clever Html helper functions which takes in lambda functions (i.e. expression trees):
Html.ActionLink<UserController>(c => c.Register(), "Register now!")
I understand that they want the keep the ASP.NET MVC framework as lightweight and simple as possible and only add features when they are really needed (which is a good philosophy) and have extensibility points for specific scenarios. However I think that a concept like controller areas should built into the framework.
I also hope they start looking at scenarios where you might want to create a modular web applications composed of multiple sub projects. I guess it would be possible to do that now but it would be very hard and would require you to replace many of the default implementations in the MVC framework.